Implementing UL2 for Decoder-Only Language Models
The dominant pretraining objective for language models has been causal language modeling. There have been alternative formulations proposed though. In particular, there have been several approaches that focused on creating a "denoising" objective (T51, UL22, FIM3). The general idea of the denoising objective is to mask or corrupt spans of text and have the model predict (autoregressively) the tokens in the corrupted spans given the uncorrupted spans of the input.
Since the corrupted spans can generally be anywhere in the text this means that the uncorrupted spans provide previous and future context for the model. This is unlike the traditional causal objective where a model can only use previous context to predict the next token.
UL2
UL2 proposed a mixture-of-denoisers approach that sought to provide a general framework that can encompass both causal modeling and denoising. They define three denoising objectives, regular denoising (R), sequential denoising (S), and extreme denoising (X) (see figure below from original paper).

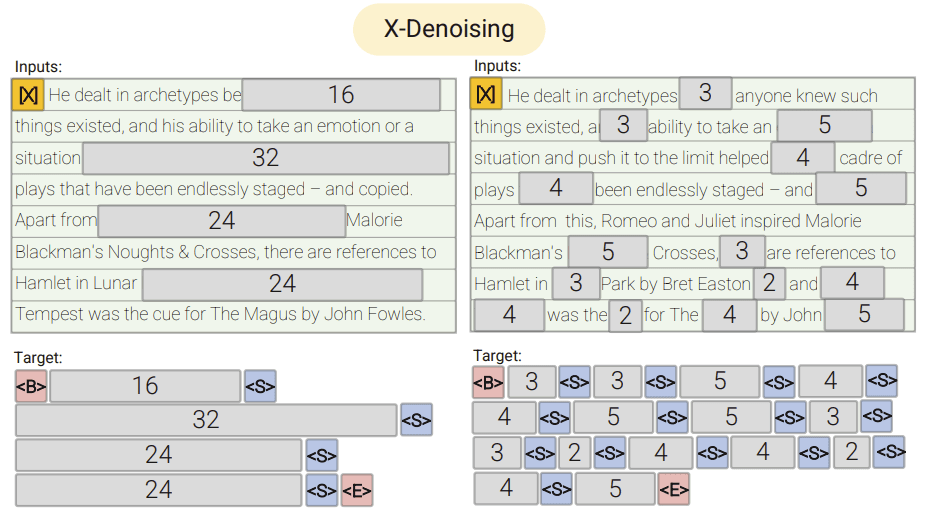
R-denoising is identical to T5 style span corruption which corrupted ~15% of tokens with a mean span length ranging from 2-5 tokens.
S-denoising is identical to "prefix language modeling" (PrefixLM) where the uncorrupted span is forced to be one contiguous sequence of tokens at the start of the input and the corrupted span is the rest of the sequence. This is very similar to causal modeling where only previous context is provided. In fact, the standard causal objective is recovered by simply setting the prefix length to 0.
X-denoising uses a high rate of corruption and/or long corrupted spans. The paper defines these denoisers to be when the corrupted spans are >12 tokens long on average or when >30% of the tokens are corrupted.
Applying a UL2 denoiser to a sequence:

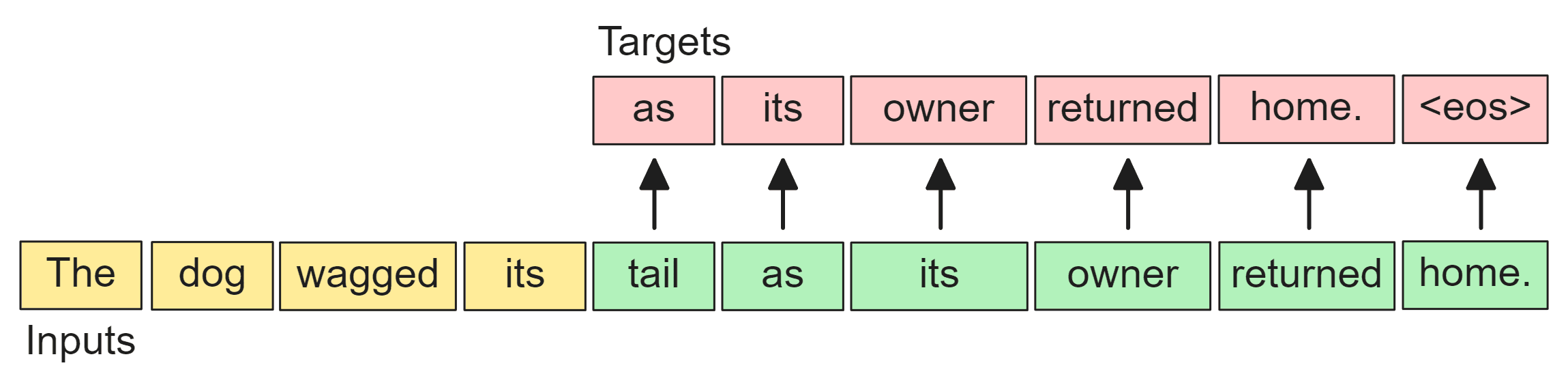
We start with the sentence "The dog wagged its tail as its owner returned home." and two random spans are selected for corruption: "wagged its tail", and "owner returned". In the bottom left sequence, the corrupted spans are each replaced with a single unique token referred to as sentinel tokens4 (i.e. <s0> and <s1>). The bottom right are the targets for this sequence where the corrupted spans to be predicted are unmasked and the uncorrupted spans are now replaced with sentinel tokens. The sentinel tokens in the bottom right sequence represent the start and stop of the corrupted the span the model is to predict. Predicting these tokens is important for letting the model indicate when it has "connected" the prior uncorrupted span to the next uncorrupted span.
UL2 also prepends a mode token (i.e. [R], [S], or [X] as shown in the paper's illustration above5) to allow the model to be prompted for mode switching. The mode token gives context to the model about the infilling task, i.e. [R] would indicate that the span the model needs to infill is relatively short.
The Encoder-Decoder View
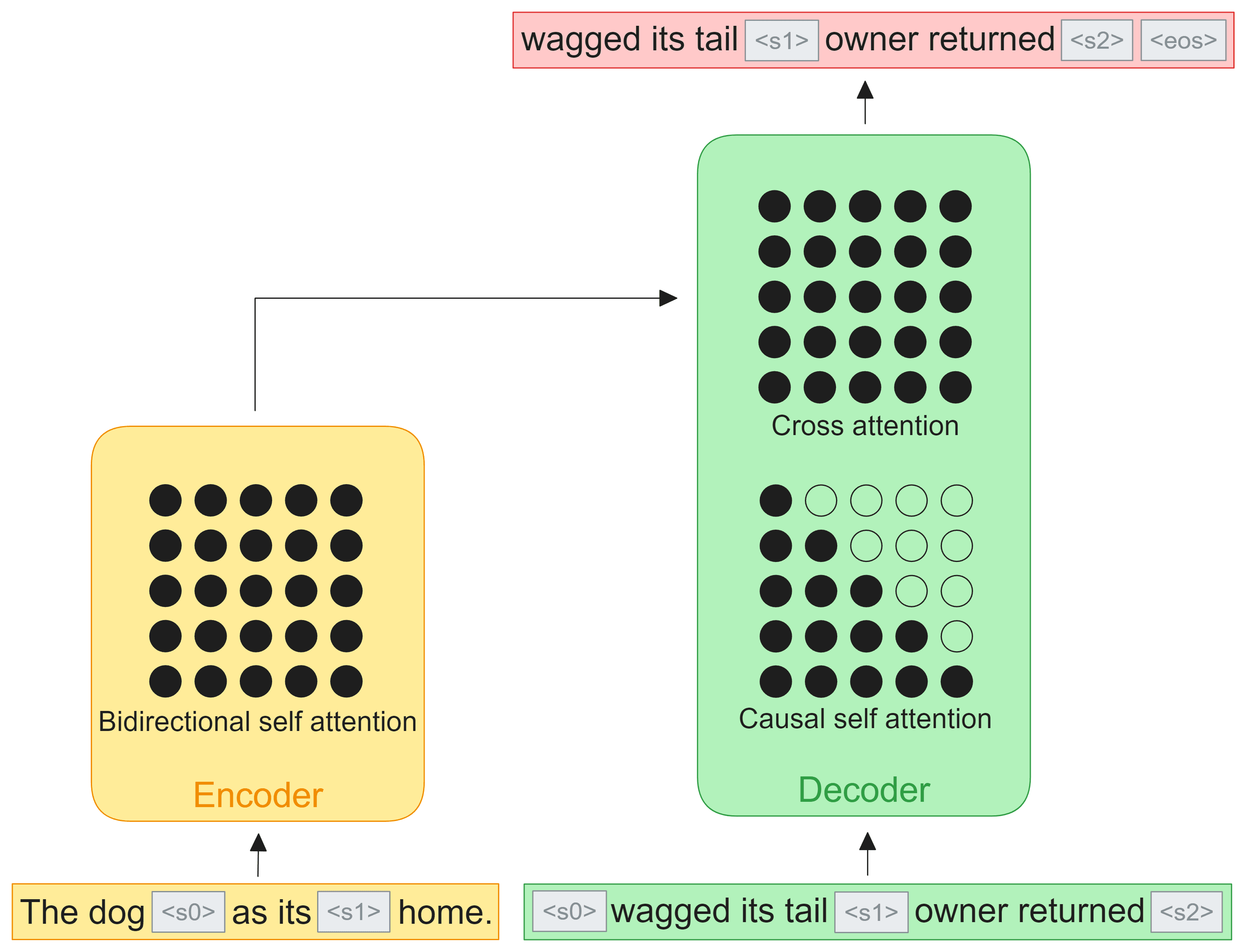
Denoising objectives are commonly associated with encoder-decoder models like T5 and UL2 (although the UL2 paper ablates the decoder-only choice too). In this setting, the corrupted version of the sequence is fed to the encoder where bidirectional attention allows all the uncorrupted tokens to attend to each other. The target sequence is fed to the decoder where the it passes through causal self attention followed by full cross attention with the encoder output. The targets (in red) are just the decoder input sequence shifted left in order to apply the otherwise normal autoregressive next token prediction objective.
The Decoder-only View
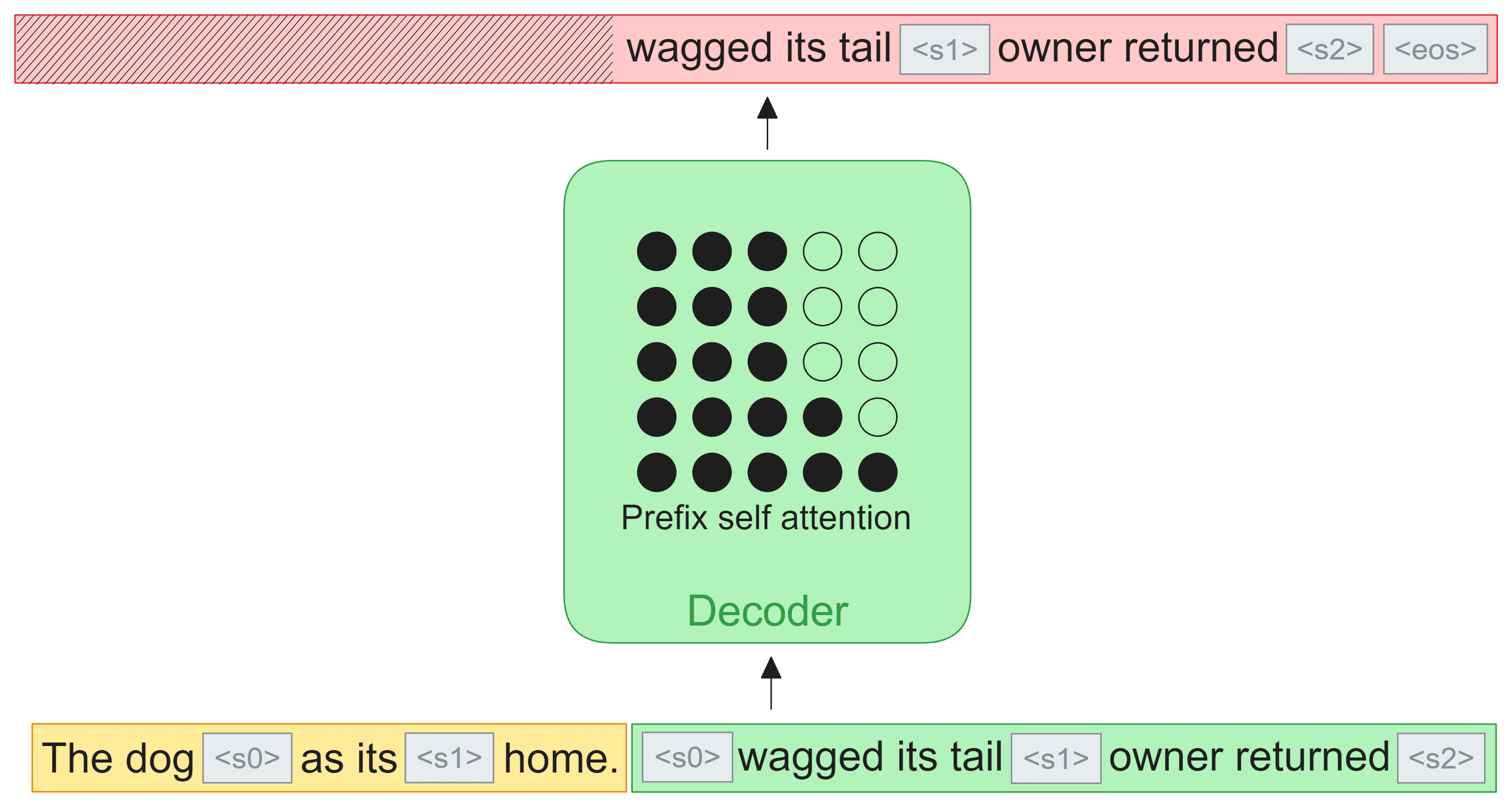
Denoising objectives are not limited though to encoder-decoder models and can easily be used in decoder-only architectures. Here the corrupted sequence is treated as a prefix and concatenated with the targets as one sequence and fed to the model. The prefix is excluded from the loss and the standard next token cross-entropy is applied on the targets. Optionally, a PrefixLM style attention mask can be used to allow for bidirectional attention across the corrupted sequence. For the rest of this post, we'll go over implementation and modeling considerations for the decoder-only setting.
Data loading
In causal LM implementations, i.e. nanoGPT (opens in a new tab), data loading can be done very easily. For example, nanoGPT expects a dataset to be pre-tokenized and concatenated into one long array (with documents separated by the <eos> token) and then constructs a batch of size [B, S] by randomly indexing into the array B times and extracting a S length span of tokens.
idx = torch.randint(len(data) - S, (B,))
x = torch.stack([data[i : i + S] for i in ix])
y = torch.stack([data[i + 1 : i + 1+ S] for i in ix])This implementation avoids the need to do any padding or packing of sequences by not taking into consideration document boundaries. This results in some sequences potentially containing one or more partial or full documents. A consequence of this is that the model could see unrelated tokens in its context. A way to deal with this is to use an attention mask to prevent the model from attending across document boundaries. According to 6 this is less of a worry in standard pre-training but becomes much more important in long-context pre-training:
We use an attention mask that prevents self-attention between different documents within the same sequence. We find that this change had limited impact during in standard pre-training, but find it to be important in continued pre-training on very long sequences.
Data loading for UL2 in the decoder-only setting can be implemented easily in a simple manner as well. First, we need to define a set of denoisers that we randomly sample with a certain probability. A denoiser is defined by a couple settings: mean noise span length and noise density (or corruption rate). Additionally, each denoiser can be assigned a mode token and probability which defines the rate at which we select that denoiser during training.
The mean noise span length is used as the mean of a normal distribution from which the corrupted span lengths are sampled. The noise density defines the number of tokens to be corrupted in the sequence which, along with the mean noise span length, then determine how many corrupted spans will be present.
# denoiser settings
# (mean, density, mode, probability)
denoisers = [
(3.0, 0.15, "[R]", 0.13),
(8.0, 0.15, "[R]", 0.13),
(3.0, 0.50, "[X]", 0.13),
(8.0, 0.50, "[X]", 0.13),
(64.0, 0.15, "[X]", 0.13),
(64.0, 0.50, "[X]", 0.13),
(None, 0.25, "[S]", 0.22),
]Note that for the S-denoiser we only need to define the density and not the mean span length since by definition we are only going to corrupt one contiguous span at the end of the input sequence. An S-denoiser density defines the mean of a uniform distribution so the maximum density we can set is 0.5 which would allow for the chance to sample a density of 1.0 which would corrupt the entire sequence and be equivalent to the standard causal language modeling objective.
In the causal LM data loader we know that to obtain a sequence length of S for our batch we simply need to extract a sequence of length S from the dataset. However, in the UL2 case, given an uncorrupted sequence length of S', the final sequence that is used as the input to the model will be of length S' + C where C = # corrupted_spans + # uncorrupted spans + 1 (for mode token) because the denoising function will add 1 sentinel token for each corrupted/uncorrupted span in the prefix and targets plus the prepended mode token. Taking our example sentence (and tokenizing by whitespace):

we have 10 tokens. After applying a denoiser it and concatenating the corrupted version of the sequence with the targets it will look like:

which is now 16 tokens.
To achieve a model input of S then we need to extract a sequence of S' from the dataset. This can be done by first figuring out the value of C. Because C actually depends on S' this can be solved iteratively given the desired sequence length of S and the denoiser settings:
def sequence_length_helper(S, mean, density):
def _post_denoiser_sequence_length(S_prime, mean, density):
num_noise_tokens = int(round(S_prime * density))
num_nonnoise_tokens = S_prime - num_noise_tokens
num_noise_spans = int(round(num_noise_tokens / mean))
return (num_nonnoise_tokens + num_noise_spans) + (num_noise_tokens + num_noise_spans) + 1 # +1 for mode token
S_prime = S
while(_post_denoiser_sequence_length(S_prime, mean, density) > S):
S_prime -= 1
return S_primeMore concretely if our desired training sequence length is 1024 then due to the additional sentinel/mode tokens that a denoiser will add, we will need to extract a sequence of length S' < 1024.
Extending the nanoGPT data loading logic to include this doesn't end up being too daunting7:
# set y array to -1 by default which is the value pytorch xentropy ignores by default
x = torch.zeros(B, S, dtype=torch.int64)
y = torch.zeros(B, S, dtype=torch.int64) - 1
for b in range(B):
denoiser = sample(denoisers)
S_prime = sequence_length_helper(S, denoiser.mean, denoiser.density)
idx = torch.randint(len(data) - random_chunk_size, (1,))
sequence = data[idx : idx + S_prime]
denoised_sequence = denoiser(sequence)
x[b] = denoised_sequence[:-1]
y[b] = denoised_sequence[1:]This will inherit the potential of crossing document boundaries mentioned earlier. There are a couple alternatives to avoid this. We could preprocess the dataset at the document-level and pad/pack sequences at runtime. Or, like the FIM3 paper did, we could separate a chunk of tokens (extracted from the dataset at runtime) by the document boundary tokens and apply denoising independently to the individual documents then reconcatenating and trimming to the context size.
Token vs. Character-level denoising
Another modeling choice mentioned in the FIM3 paper that could be applied to UL2 is whether to apply denoising at the token-level or the character-level. While UL2 is typically applied at the token-level (I don't know of any UL2 implementations at the character-level in fact), there could be some advantages of denoising at the character-level, especially when we look at a setting of infilling/completing code. Take this string of code for example:
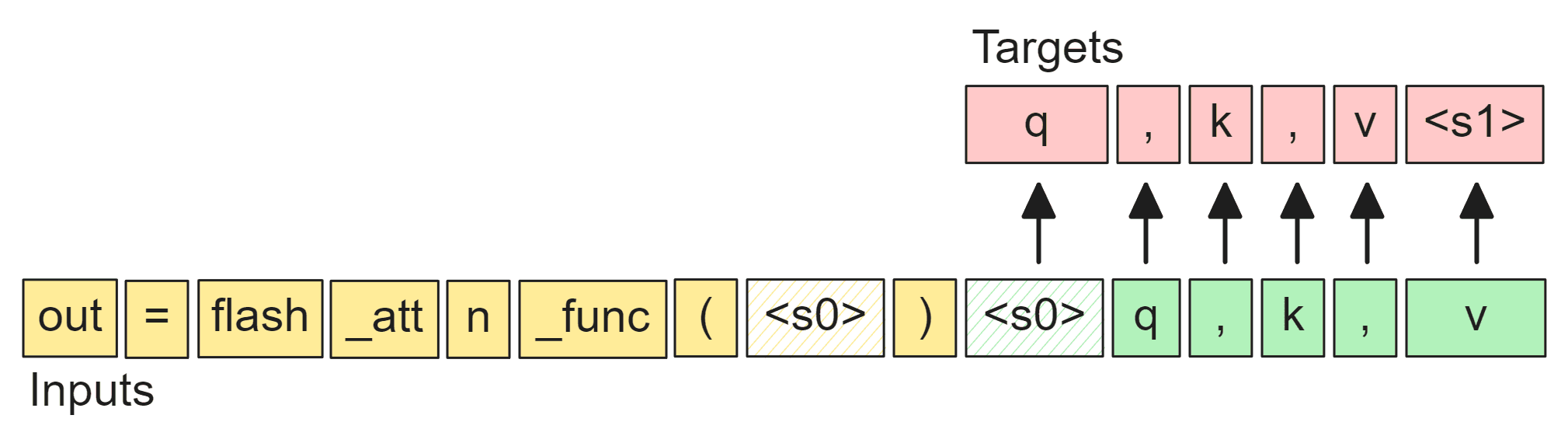
out = flash_attn_func(q, k, v)
If this is tokenized by the GPT-4o tokenizer:

Denoising at the token-level can result in missing cases where a token is broken into two tokens. Given the tokens above, there could be a corrupted span like:

Note that the starting parenthesis of this function is tokenized along with q into (q. However, in a real world coding copilot scenario where we ask the model to infill the arguments to the function, the tokenization of the input would have the starting parenthesis as its own token:
By denoising at the character-level in training we could include more of the subtoken boundaries. This comes with a bit of added complexity though because it would have to be done by preprocessing the dataset at the document-level or done at runtime on a random chunk of tokens. This would require decoding the already tokenized sequence, applying the character-level denoising, and then re-tokenizing.
The role of sentinel and mode tokens
As I was first reading and implementing UL2, I initially had the question of "do we want the model to predict sentinel tokens?" or in another words when the next token in the target sequence is a sentinel token, should we mask it out from the loss? After all, we don't want the model to spit out sentinel tokens that look meaningless or confusing to user. Learning to predict the sentinel tokens though is actually quite important for the model to reliably learn the task and to behave well at inference. A sentinel token allows the model to signify that it thinks it completed the infilling for the corrupted and that it has "connected" the surrounding uncorrupted spans of text. This is similar to using an <eos> token to know when the model has completed its generation. Take our code infilling for example again, at inference time we ask the model to fill in the parameters to the function call with typical autoregressive decoding until it predicts the next sentinel token:

Mode tokens can also serve an important role for the model. The mode tokens are assigned to the three classes of denoisers that are characterized by their mean length of corrupted spans and their corruption rate. By training with mode tokens we can condition model to know the class of problem it's dealing with. For example, when given the mode token [R], the model knows that the spans it needs to predict are relatively short and that the prefix portion of the sequence is relatively uncorrupted and probably encodes a high amount of meaningful information that it needs to understand. Meanwhile, with the [X] mode token, the model knows that the corrupted spans then are either quite long or very frequent and that the prefix encodes a sparser amount of information.
As the UL2 paper points out, the mode tokens can "bind" model behavior on downstream tasks to these modes of operation learned in pretraining. But lack of a mode token can do this too. For an S-denoiser (PrefixLM) we can completely forego using a mode token and sentinel tokens. With a mode and sentinel tokens included our model input looks like:

However, the sentinel tokens are redundant and could be consolidated into one or even none. The mode token can also go which will effectively "bind" our model behavior to standard open-ended autoregressive generation at inference time when no mode token is given. Our training data would now look like the standard PrefixLM formulation:
Another consideration is how to pick a mode token at inference time. For existing benchmarks this can be easy since we typically know characteristics of the test data and the task definition beforehand. But deciding between the R-denoiser and X-denoiser modes may not be so obvious in the wild. Take for example again the setting of code infilling from earlier, where we ask the model to fill in the parameters of a function:
out = flash_attn_func(<s0>)
It's hard to infer a priori if the function parameters will be only a few tokens or a much longer span. In the default UL2 settings though, the X-denoisers do include short spans (with high corruption rates) and long spans, so that could be a good default. Regardless though, the choice of how mode tokens are used in training should of course be informed by the expected downstream use of your model.
Attention mask
In order to mimic the bidirectional nature of an encoder on the prefix, a PrefixLM style attention mask can be used in the decoder-only setting (as illustrated earlier). This allows tokens in the prefix portion of the sequence to attend to both past and future tokens while still maintaining a causal mask on the target portion of the sequence. There was notably though the lack of an open source fast and memory efficient PrefixLM attention implementation (i.e. flash attention). Recently though, the introduction of FlexAttention8 in PyTorch has allowed for this to be easily implemented now.
The PrefixLM attention mask is not a requirement though and a standard causal mask can still be used. At least one example of a UL2 trained decoder-only model that used a causal attention mask is OpenMoE9.
Training signal density
A downside to UL2/denoising objectives is that for a given sequence length in training, there is only a portion of the tokens that take part in the loss.10 Take our example targets and input sequence:

The -1 values means these positions are masked out from the cross-entropy loss. So here only 7 of the 15 tokens take part in the loss whereas in the standard causal objective we are able to have all input tokens take part. A potential way to mitigate this could be to still apply the loss on the uncorrupted spans in the prefix, especially with R-denoisers which have long uncorrupted spans of tokens that could be recruited (but not when using the S-denoiser since it would defeat the purpose of PrefixLM). This would require using fully causal attention instead of bidrirectional prefix attention however.
Related reading
Besides the original UL2 paper, here are some other great resources:
Transcending Scaling Laws with 0.1% Extra Compute11: Continued pre-training of PaLM (a decoder-only causal LM) with UL2 objectives.
OpenMoE: An Early Effort on Open Mixture-of-Experts Language Models9: One of the only open source decoder-only efforts to use UL2 and uses causal attention. Their mixture of denoisers differs a bit from the original UL2 paper.
What happened to BERT & T5? On Transformer Encoders, PrefixLM and Denoising Objectives10: Lots of valuable insights from Yi on a variety of related topics, especially on UL2/denoising, some of which I mentioned earlier.
Footnotes
-
Raffel, C., Shazeer, N., Roberts, A., Lee, K., Narang, S., Matena, M., Zhou, Y., Li, W., Liu, P.J. Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer (opens in a new tab). arXiv, 2019. ↩
-
Tay, Y., Dehghani, M., Tran, V.Q., Garcia, X., Wei, J., Wang, X., Chung, H.W., Shakeri, S., Bahri, D., Schuster, T., Zheng, H.S., Zhou, D., Houlsby, N., Metzler, D. UL2: Unifying Language Learning Paradigms (opens in a new tab). arXiv, 2022. ↩
-
Bavarian, M., Jun, H., Tezak, N., Schulman, J., McLeavey, C., Tworek, J., Chen, M. Efficient Training of Language Models to Fill in the Middle (opens in a new tab). arXiv, 2022. ↩ ↩2 ↩3
-
Sentinel tokens can be special reserved tokens in the models embedding/unembedding matrices. It's also possible to reuse rare tokens at the end of the vocabulary like in U-PaLM. ↩
-
The mode tokens actually used for the UL2 model were
[NLU]("natural language understanding") for the R-denoisers,[S2S]("sequence-to-sequence") for S-denoisers, and[NLG]("natural language generation") for X-denoisers. ↩ -
Llama Team. The Llama 3 Herd of Models (opens in a new tab). arXiv, 2024. ↩
-
This code is a modified verions of t5.data.preprocessors.random_spans_helper (opens in a new tab) to support decoder-only considerations. ↩
-
He, H., Guessous, D., Liang, Y., Dong, J. FlexAttention: The Flexibility of PyTorch with the Performance of FlashAttention (opens in a new tab). 2024. ↩
-
Xue, F., Zheng, Z., Fu, Y., Ni, J., Zheng, Z., Zhou, W., You, Y. OpenMoE: An Early Effort on Open Mixture-of-Experts Language Models (opens in a new tab). arXiv, 2024. ↩ ↩2
-
Tay, Y. What happened to BERT & T5? On Transformer Encoders, PrefixLM and Denoising Objectives (opens in a new tab). 2024. ↩ ↩2
-
Tay, Y., Wei, J., Chung, H.W., Tran, V.Q., So, D.R., Shakeri, S., Garcia, X., Zheng, H.S., Rao, J., Chowdhery, A., Zhou, D., Metzler, D., Petrov, S., Houlsby, N., Le, Q.V., Dehghani, M. Transcending Scaling Laws with 0.1% Extra Compute (opens in a new tab). EMNLP, 2023. ↩